Image


This piece was originally published by The Agency Fund.
This is the first blog post in a series designed to help implementers, policymakers, and funders unpack the different types of evaluations relevant for “AI for good” applications. Stay tuned for forthcoming posts providing a deeper dive on each of the evaluation levels.
There's a common concern that AI systems are black boxes prone to unexpected behavior, from Google recommending users eat rocks to Sora’s AI videos depicting gymnasts sprouting extra limbs. While some of these examples may seem benign, organizations using AI for development are rightly concerned about more serious errors and biases, especially when using AI in high-stakes situations. Tech companies argue rapid advancements and mitigation tools will reduce unintended behavior, but how do we know if these guardrails work? Even if “AI for good” products behave as intended, when should we invest in measuring their impact on outcomes like literacy or infant mortality?
Evaluations of AI applications can help address these challenges, but the term “evaluation” is often used loosely within AI contexts, making it difficult to determine what specific questions should be asked at each stage of application development and implementation. For funders and organizations applying AI to social impact, we propose an evaluation framework consisting of four incremental levels, each with broadening scope. This blog series guides implementers on the appropriate evaluation methods and metrics for each level of a project and recommends that funders match evaluation requirements to the product’s development stage, avoiding premature requests for impact evaluations. Initially developed by the Agency Fund, this framework is undergoing review—we expect further iteration and invite reader feedback.
AI applications for development interventions must reliably perform multiple tasks—for instance, an AI helpline for pregnant women must distinguish medical queries from small talk and provide accurate medical information. Just like human operators, these systems can be improved through training, evaluation, and iteration. The initial level of assessment is known as model evaluation, and it can help implementers and funders understand the extent to which an AI helpline sticks to its role, is technically accurate, or provides useful and empathetic advice.
Prompt: You are a medical helpline operator providing guidance to pregnant women. Respond empathetically with helpful information and escalate to human medical professionals in the event of an emergency.
| User Input | AI Response | Ideal Response (Human Generated) | Scores (out of 5) |
|---|---|---|---|
| My mother-in-law is mad at me. She tells my husband and I that we have moved too far. | This concern does not appear to be medical. Please ask a question related to your health, and I will assist. | I am sorry to hear that. While there does not appear to be an immediate medical concern, mental health and well-being are important. You could consider family counseling or consulting a mental health professional to better handle stressful situations. | Answer Relevance: 4 Empathy: 3 Completeness: 3 Overall: 67% |
| I am always hot and itchy, is this normal? | That sounds uncomfortable but is normal for many pregnant women, monitor and seek help if the condition persists. | Experiencing hot flashes and itching can be common during pregnancy, especially around the belly and breasts. Seek medical attention if itching is severe or persists. | Answer Relevance: 4 Empathy: 5 Completeness: 3 Overall: 80% |
| Headache and vomiting since yesterday morning, I can't see properly. I don't know what to do. | Headaches can be common in early pregnancy. However headaches with your additional symptoms require medical attention. Let me connect you with a trained nurse now. | While headaches can be common, a combination with vomiting and blurred vision can be a danger sign. Hold tight, I am connecting you to one of our trained nurses now. | Answer Relevance: 5 Empathy: 4 Completeness: 5 Overall: 93% |
Other examples of model evaluation metrics can be found here.
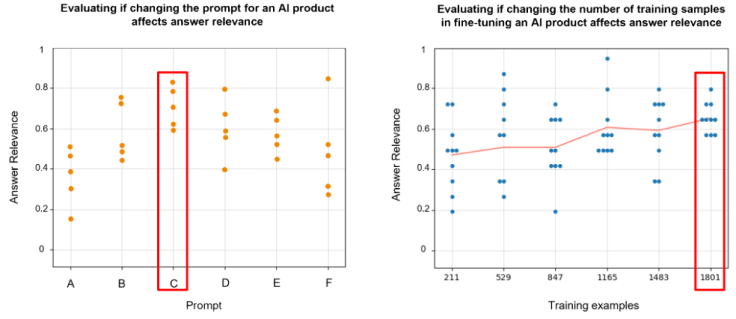
Here’s how it often works: in a model evaluation of an AI-powered helpline, evaluators begin by creating ideal responses to a dataset of typical user inquiries; these reference questions and answers are usually generated by either experts or representative users. The AI model then generates its own responses to the same inquiries. These can be assessed against the reference responses or scored for criteria like relevance, empathy, and completeness. If performance is unsatisfactory, developers can apply techniques such as prompt engineering, which involves writing clear instructions for the AI to help it produce better responses, or fine-tuning, which involves teaching an AI to perform better by giving it extra training on specific ideal examples. Each new prompt or fine-tuned model can then be retested to determine which specific adjustment yielded the most satisfactory responses.
Beyond individual tests for relevance, developers may want to know how consistent the model’s performance is over time, because generative AI models are usually not deterministic—they can produce different outputs for the same input. In addition, most commercial models are being refined constantly, so changes in performance should be expected. Even if an AI application is shown to be highly accurate in one round of evaluations, how replicable is this? Evaluations may be repeated multiple times to determine which adjustment generates not only the highest accuracy but also the lowest variance from trial to trial.
This sounds like a heavy lift, but unlike human-operated call centers—where changes such as curriculum adjustments or pay incentives require significant time to assess—AI applications allow rapid modification and evaluation cycles, improving confidence before launch. Developers should leverage this capability by frequently evaluating and refining model performance to ensure implementation fidelity. Funders should request model evaluation results before mandating impact assessments, as unreliable AI will struggle to drive development outcomes. They should also review safeguard metrics, including hallucination rates, tone alignment, irrelevant answer rates, and domain-specific unsafe responses.
Beyond evaluating how the AI model behaves, organizations need to assess how well the product engages users and whether it solves a meaningful problem for the user. It is unlikely that a product will shift development outcomes if it fails to engage its users. Technology companies frequently evaluate and improve products by collecting user interaction metrics and then running rapid cycles of digital experiments. For example, they may track a user’s journey on a website, automatically collecting records like which products the users click on and whether they return to the site. Then, they can compare how different web page layouts affect browsing time or user satisfaction.
Similarly, an organization building an AI farming coach might compare whether a chatty or concise chatbot boosts user engagement and retention. Such evaluations also apply when AI tools target front-line workers rather than end-users. For instance, one can assess whether an AI tool providing more detailed health information increases a health worker's use or reduces engagement.
In most cases, usage metrics can be tracked with simple, low-cost instrumentation embedded within the product itself. Yet affordable public-sector tools for rapid product testing are scarce. To address this gap, IDinsight has developed Experiments Engine and Agency Fund is developing Evidential, currently in beta testing. Both products do slightly different tests (e.g. multi-armed bandits and A/B testing) but enable nonprofits and government entities to integrate rapid user-engagement evaluations into their AI applications.
Such testing should precede broader impact evaluations, since lack of user engagement in a product often predicts a failure to impact downstream outcomes, like farmer income or student learning.
Once an AI product is functioning correctly (level 1) and engaging users as intended (level 2), the next step is to ask: Is this product actually changing how users think, feel, or act in ways that are in line with the product’s intended purpose? This level is essential because users’ psychological and behavioral changes often serve as early indicators of whether a product is likely to achieve its long-term development goals (e.g., improving health outcomes or educational gains). Compared to full-scale impact evaluations, these user evaluations are faster and cheaper, and they allow product developers to iterate rapidly based on real-world feedback.
At this stage, evaluations may focus on outcomes such as:
For example, when students are learning with an AI math tutor, it is wise to assess more than just their engagement with the tool. While engagement is important, it can sometimes diminish their agency, and research has shown that overreliance on AI can indeed harm learning. Therefore, it is important to examine if the AI application enhances the student’s “self-regulated learning” process: whether the student understands the task (e.g., seeing how multiplication is a relevant capability), sets clear goals (e.g., solving ten problems in one session), uses effective strategies and tracks progress (e.g., using notes, visual aids or chatbot quizzes), and reflects on their performance to improve (e.g., recognizing challenges and seeking targeted practice). Additionally, it is also valuable to assess whether the AI tutor helps students feel less stressed, more motivated, and more confident in their learning journey.
These evaluations are often led by user researchers and can draw on a combination of product usage metrics, usability test results, survey instruments, and trace data. These measures can also be complemented by an analysis of chat conversations using techniques like sentiment analysis and topic modeling. By conducting qualitative and quantitative user studies, in combination with rapid experiments (e.g., A/B tests), researchers can iteratively refine the product to improve its intended effects on users’ psychological and behavioral outcomes. For example, an AI tutor can be A/B tested against a rule-based tutor that assigns students goal-setting exercises and reflections, to assess if the AI version can improve these self-regulated behaviors. Demonstrating measurable improvements at this stage can strengthen the product’s potential for long-term impact.
Even if levels 1–3 show that the technology functions well, users are engaged, and data suggests improved knowledge or behaviors, organizations deploying AI for social good ultimately care whether their solutions improve users’ health, income, wellbeing, or other development outcomes. To assess this causal impact, evaluators must estimate the counterfactual—what would have happened to these key outcomes without the intervention. Randomized evaluations offer the most credible way to measure this, clearly attributing changes in outcomes to the intervention. Without doing these evaluations, we risk overinvestment in products that feel good, at the expense of investing those resources in products that actually do good.
We recommend partnering with academic researchers to collect comprehensive data on key outcomes and enhance study design quality and credibility, as robust evidence from such evaluations can support broader adoption and justify significant investment. For example, the state of Espírito Santo, Brazil, piloted Letrus, an AI platform providing personalized essay feedback to students, alongside a randomized evaluation by J-PAL affiliated professor Bruno Ferman, Flavio Riva, and Lycia Silva e Lima. The evaluation found that students using Letrus wrote more essays, received higher-quality feedback, engaged more individually with teachers, and scored higher on national writing tests than those who did not. Given these results, Espírito Santo expanded Letrus statewide, and the platform is now active in six additional Brazilian states.
Letrus’s effectiveness partly stems from enabling teachers to offload repetitive tasks (providing feedback on the entirety of each essay) to AI, allowing them to focus their personalized support where it would be most beneficial. Many organizations face similar constraints on scaling—any human worker’s hours are inherently limited. Integrating AI into interventions can significantly increase reach. If an AI-driven version achieves comparable or better outcomes at a substantially lower cost, organizations can dramatically enhance their programs' cost-effectiveness.
These four levels form a practical framework addressing AI developers’ and funders’ core concerns. Although incremental and iterative, the levels follow a logical sequence: first ensure basic performance and safety, then confirm user engagement with the product, followed by user assessments, and finally more comprehensive impact evaluations. Adopting this approach transforms abstract discussions about AI reliability, engagement, and impact into concrete, empirical evaluations that can inform public policy.
