Image


From Teaching at the Right Level to the multifaceted Graduation approach, J-PAL’s affiliated researcher network has helped to evaluate a diverse range of innovative interventions aimed at reducing poverty over the past twenty years. But the innovations aren’t limited to the interventions themselves. Researchers worldwide have also made important advancements in the methodology of randomized controlled trials (RCTs) to generate better quality evidence. At J-PAL’s 20th anniversary celebration at MIT in November 2023, we held a panel discussion on RCT innovations with researchers who are utilizing new data sources, analytical methods, and study designs to move RCT research forward. In this blog, we share insights from this session and reflect on the future of innovation in RCT methods.
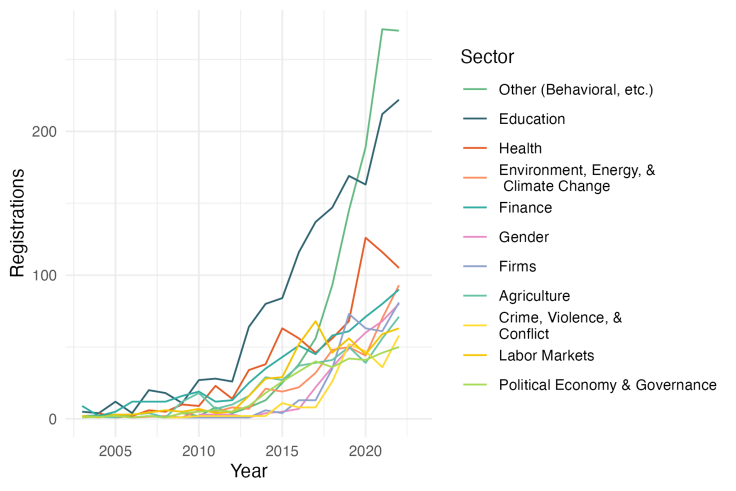
The rise in the number and geographic reach of RCTs in the social sciences over the past two decades is striking, expanding ten-fold to over 1000 studies annually across 167 countries in 2023 (as proxied by registrations in the AEA RCT Registry). This accumulation of evidence has promoted further learning and innovation across sectors by allowing researchers to continually build on existing studies and develop new techniques to create more robust evidence. During this period, we have seen not only dramatic increases in evidence generation, but also important advances in the way that we conduct RCTs to address new and existing challenges. Notable innovations cover a range of research areas, from access to new data sources to new approaches to experimental design and data analysis.
Together with session moderator William Parienté, professor at UCLouvain and Chair of J-PAL’s Research vertical, we invited four panelists to present on innovations impacting how RCTs might be run in the next decade. To start, Craig McIntosh discussed cash benchmarking for cost-benefit comparisons across studies, Seema Jayachandran then presented her work on validating survey measures of abstract constructs, Poppy Widyasari advised on using administrative data in experiments, and, finally, Dean Karlan highlighted megastudies and multi-site studies to address incentive issues in large coordinated studies.
Craig McIntosh, professor at the University of California, San Diego and co-chair of J-PAL’s Agriculture sector, emphasized a need to better inform policy-making by shifting from benefits-focused evaluation to include a more comprehensive consideration of costs. Much of the work on cost-effectiveness focuses on collecting cost data during or after implementation and comparing these figures across programs. There are, however, challenges in comparing diverse studies, where samples, outcomes, and scales can vastly differ. As a solution, Craig and his team sought to make more direct cost comparisons by designing cash transfer equivalents for in-kind child nutrition and workforce readiness programs to study how well cash transfers would perform against their non-cash counterparts. Because cash transfers have a clear cost and proven impact on multiple outcomes, they can provide an easily transferable comparison point for the cost-effectiveness of alternative interventions.
Looking toward the future, Craig proposed that eventually it would be possible to do a careful meta-analysis of cash transfer evidence to create a simulation tool allowing researchers to predict a distribution of cash impacts across a set of outcomes. This would reduce the cost of future research by simulating the impacts of an equivalent cash transfer treatment arm, and could be continually updated as new evidence comes in. There is still much to learn about the cost-effectiveness of cash transfers, with Craig using findings in his own studies to remark on potential difficulties, including cases where effectiveness may not increase at the same rate as cash distributed.
Seema Jayachandran, professor at Princeton University and co-chair of J-PAL’s Gender sector, presented her work on developing a systematic way to identify survey measures most predictive of more abstract constructs like women’s empowerment. To measure these types of constructs, researchers typically design an index containing several close-ended questions on the topic. The issue is in knowing what questions to include in these modules. To address this, Seema and an interdisciplinary research team developed a two-stage process. First, they created a benchmark measure of women’s empowerment using qualitative data from in-depth interviews. They then used machine learning algorithms to identify items from widely used questionnaires that best predicted women’s empowerment when compared to their benchmark.
The index created from this study, while still context-specific, proved that it is possible to create short survey modules that provide valid measures of complex constructs. This model has a number of potential benefits, including reducing the cost of data collection and allowing easier harmonization of data across studies. Going forward, applying this model in different contexts to identify universally established indices for complex constructs could significantly enhance measurement consistency across different studies and sectors.
The growing accessibility of administrative data in recent years presents a promising avenue to facilitate intervention delivery, monitor program implementation, and measure outcomes at increasingly large scales. Poppy Widyasari, Associate Director of Research at J-PAL Southeast Asia (SEA), demonstrated how J-PAL SEA has used administrative data to mitigate measurement error and improve cost efficiency at different stages of the research process. Recognizing that successful partnerships often require initial investments in infrastructure, Poppy provided insights for navigating the complexities of obtaining and integrating administrative data into research projects. This includes creating a plan for accessing data, preparing for data lags, and building partnerships with data providers to work toward shared goals.
Administrative data may often be collected by governments and other agencies at broad scales, such as tax filings or school records. Planning ahead to take advantage of these sources is key to successfully leverage administrative data in randomized evaluations. Poppy also underscored the importance of relationship building, highlighting establishing trust with government partners as a critical first step. The use of administrative data allowed J-PAL SEA to pursue studies on a national scale in Indonesia, something that would be extremely costly and time consuming to do through traditional survey methods. In these studies, the research teams were able to use census data to identify eligible beneficiaries, banking data to monitor program implementation, and social security transaction data as an intervention outcome.
Dean Karlan, professor at Northwestern University, proposed two solutions to improve the replication, validation, and synthesis of lessons learned across experiments: megastudies—in which many interventions are implemented at once targeting the same outcome in the same population—and multi-site studies—in which the same intervention is implemented across different populations. Currently, most evidence synthesis is done through meta-analyses, but this can lack the oversight of the research process needed to make clear comparisons between studies. Megastudies and multi-site studies coordinate data collection efforts and costs to build out additional research, taking advantage of large sample sizes across multiple locations to enhance validity and reduce variation across experiments.
Although megastudies and multi-site studies may seem prohibitively costly, Dean and the panel noted that there are opportunities to innovate for more efficient studies. One example is leveraging administrative data from platforms like social media and mobile banking, where the fixed costs of obtaining data can be covered by a single party, and repeated studies by other researchers can build off of these data structures. Another is partnering with large NGOs and international organizations that operate across countries, where additional interventions can be overlaid on existing programs across multiple sites, easing the cost of one extra site and offering tremendous opportunity for scaling research coordination.
While attempting to cover the full range of innovations over the past twenty years would require an encyclopedia-length blog post, it’s worth acknowledging some of the notable innovations that we weren’t able to cover in our panel. The adoption of machine learning techniques has allowed researchers to take advantage of larger and more complex datasets as well as improve our understanding of treatment effect heterogeneity and causal inference. Experiments may also now test large sets of interventions at once or contain an adaptive component for more tailored interventions. Making use of the large stores of existing evidence, there are also innovations that aim to aggregate lessons across studies and enhance research transparency and reproducibility.
These and collective insights from the panel underscore innovations in RCT methods that continue to evolve and propel the methodology forward. These novel approaches not only showcase progress made to date but also point toward collaborative and systematic approaches that will shape the future of RCT research. As we navigate challenges and embrace changes to the methodology, these innovations present promising solutions to enhance the generation, synthesis, and policy impact of evidence. With ongoing shifts in the landscape of RCT research that may have seemed like a moonshot twenty years ago—like ways to measure long-term and large-scale impacts, explore more ethical and accurate data collection, and introduce new data sources—we look forward to the future of this work to push the frontiers of research and learning.

