Imagen


We conduct RCTs to learn. However, the programs we evaluate are often based on strong, evidence-informed theories of change resulting in a hypothesis that the program will have an impact. Therefore, it can be surprising—and disappointing—to run that golden regression only to learn that the impact of the program was not statistically different from zero.
While a null result is likely not what you were hoping for, and while null results can (unfortunately) be more difficult to publish, they can spur just as important insights and policy implications as significant results. However, to learn from a null result, it is necessary to understand the why behind the null. This blog proposes a series of steps that can get you closer to understanding what drives your null result, distinguishing between three explanations: imprecise estimates, implementation failure, and a true lack of impact.
Establish whether you are dealing with a tightly estimated null effect—a “true zero,” as Dave Evans calls it—or a noisy positive/negative effect. A tightly estimated null effect can be interpreted as “we can be fairly certain that this program did not move the outcome of interest,” (i.e., there is evidence of absence of an effect) whereas an insignificant positive/negative effect can be interpreted as “we cannot really be certain one way or the other,” (i.e., there is absence of evidence of an effect).
The following checks can help you determine whether your null result is a “true zero:”
If your null result is tightly estimated, well-powered, not caused by data issues, and consistent across outcome specifications and subgroups, your result is likely to be a “true zero” and you can move on to the next steps.
If not, consider whether there is anything you can do to improve the data quality or the power of the study. Take a look at J-PAL's resources on data cleaning and management and power.
Once you have established that your result is, indeed, a “true zero,” the next step is to establish whether the null result is driven by what evaluation expert Carol Weiss has described as a failure of ideas vs. a failure of implementation.
A good process evaluation can help determine whether your null result is caused by implementation failure:
To answer these questions, look at all implementation or process data you can get your hands on. It can also be valuable to interview implementers and recipients to see how they understood and engaged with the program. Ideally, some of this data has already been collected as part of the ongoing process evaluation, but you might need to go back and ask additional questions.
If the program was delivered as intended and had sufficient take-up, it is likely that the null result is caused by the program not having the hypothesized effect. The next step is to dig deeper into the theory of change to understand why that might be.
If not, your null result might be caused by implementation failure. In this case, it can be difficult to draw conclusions about whether the program would have worked had it been implemented as intended. Instead, consider using what you learned through your process evaluation to improve the program implementation.
Even a high-quality theory of change, which is informed by strong evidence, is full of assumptions.
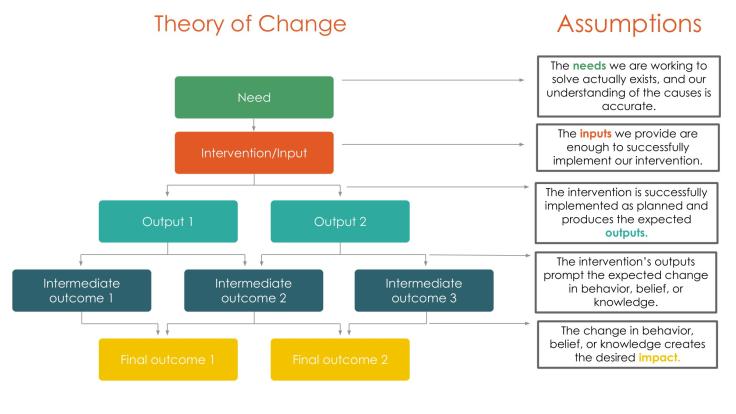
If you ruled out that the null effect was caused by imprecision of the estimate and implementation failure, the next step is to revisit all implicit and explicit assumptions in the theory of change to try to pin down what could have broken the causal chain.
Given the nature of assumptions, this step involves forming hypotheses about which assumptions are likely to not have been met. Ideally, you will be able to test these hypotheses, either with existing data or by going back to collect more data (quantitative or qualitative) from implementers, recipients, experts, etc. You can also consider running additional experiments to explicitly test these hypotheses.
A general implication of a null result is that the program should not be scaled up, as is, in the given context. However, a null result does not mean you should automatically abandon the program altogether. What you can do with the null result depends on the why of the null:
Finally, what you learned about the necessary conditions for program impact can be used—if properly communicated and not filed away in a drawer—to assess the limits to the generalizability of the program and to help design future programs, both in your context and in others. Don't let a null result discourage you; instead, use it as an opportunity to refine and advance your work.

