Image


Innovate, test, then scale. The sequence seems obvious—but is in fact a radical departure. Too often the policy making process looks more like “have a hunch, find an anecdote, then claim success.”
Over the last decade and more, though, many individuals and organizations have invested in this new model of development. We’ve learned a lot including about how to improve learning, reduce extreme poverty, combat violence, and improve women’s empowerment.
But what have we learned about the process of getting from innovation to scale? What kinds of innovations make it to scale? What types of partnerships are needed? What can donors do to catalyze policy impact at scale?
The “graduation” program is an example of what I consider the classic model for the “innovate, test, scale” approach. The Bangladeshi NGO BRAC realized that some people are too poor to benefit from microfinance. They designed an innovative program that provided very poor people with assets, a small stream of income, and intensive support—designed to help families “graduate” to a higher-income status. This program was tested with a randomized evaluation, which showed that it was spectacularly effective (Bandiera et al).
Researchers then coordinated to test the impacts of the program in six other countries. The findings from randomized evaluations, taken together, demonstrated highly positive cost-benefit ratios: In other words, the program was found to be not only broadly effective, but also cost-effective (Banerjee et al 2015, summarized here).
With these positive findings from rigorous research, BRAC and other organizations implementing the graduation approach were then able to use this evidence of effectiveness to raise more funding. Many were able to scale up their programs, including with support from USAID DIV and USAID’s Office of Microenterprise Development.
Direct scale-ups and adaptations now reach over 2.5 million people
So, is this the recipe for moving from innovation to testing to scale: Evaluate a program, work with an organization that can scale, replicate in multiple contexts, and scale to improve millions of lives?
That model can work. It was appropriate for the graduation program, which is expensive and thus required a higher burden of evidence of effectiveness before scaling. The graduation program is also very complex implying the results may well vary by implementer, so it is worth testing with several implementers and scaling with those implementers who saw success.
But we shouldn’t conclude that this is the only model for getting to scale. In the rest of this post I will discuss examples of the “innovate, test, scale” approach in which there was no need for replication in multiple contexts; others where the testing was (appropriately) done with a different type of organization than that which scaled it; and finally, examples of evidence impacting millions of lives when it was not a program that was tested, but a theory.
When does it make sense to scale without testing in multiple contexts?
In Indonesia, the government partnered with researchers and the World Bank on a program called Generasi that gave grants to communities to help them improve health and education outcomes. Communities could decide how to spend the money, but in some communities, the size of future payments was directly linked to measurable improvements in in education and health outcomes.
A consortium of funders including the Government of Indonesian and the Government of Australia funded testing of program, which was randomized over 264 sub-districts in five provinces in Indonesia, reaching 1.8 million beneficiaries.
Even without additional testing, the results, which showed success, were already representative of a large part of Indonesia. While it might be interesting to look at this approach in other countries, for the Indonesian government, this constituted sufficient evidence to take it to scale. The program is now improving the lives of 6.7 million women and children, with scale-up led by the Indonesian government and supported by the U.S. Millennium Challenge Corporation.
Generasi shows the benefit of testing a program with a government who can take it to massive scale. But that is not the only route to scale.
In the case of school-based deworming, a randomized evaluation tested the impact of a relatively small NGO program, but the program was successfully scaled up with multiple implementing governments. In 2016 in India alone, the government dewormed 179 million children, with technical assistance from Evidence Action supported by funding from USAID.
Of course, it’s possible that the impact of a program may be very different if the implementer changes. This is a serious concern with complicated programs that are highly dependent on personal interactions between staff and beneficiaries. But here, we are talking about a pretty simple intervention. The deworming pill used in these programs is unlikely to have different impacts if it is administered by, say, a government instead of an NGO. What is important to test is whether the pill is actually reaching people, something that Evidence Action takes very seriously and tracks carefully.
There was another reason deworming reached such large scale: Deworming children is by far the most cost-effective way to increase schooling of any program rigorously evaluated. Even with very conservative cost assumptions, US$100 spent on deworming was estimated to lead to twelve additional years of schooling. Even if worms were half as common in the next context, and costs were much higher per child, it would still be extremely cost-effective. (Costs have actually been much lower at scale.)
The lesson from deworming is that low-cost, easy-to-implement programs, if they are effective, are easier to scale up across organizations and contexts and thus have the potential to reach massive scale. The other lesson is that support for technical assistance from knowledgeable partners like Evidence Action to help governments scale is a high-leverage investment for donors.

The examples I’ve noted so far have been cases of scaling up a program that was rigorously evaluated. But I think the most profound way in which evidence has changed lives is not through the scale-up of individual programs, but through evidence changing how we understand and address problems.
Let me give you an example.
One of the first of a new wave of RCTs in development looked at the impact of providing textbooks in Kenyan schools. The authors found that textbooks only helped the top of the class, because most of the class was so far behind the curriculum they could not read the textbooks. So next, academics tested a program called “teaching at the right level” that sought to help those children who had fallen behind, implemented by an NGO called Pratham in India. The results were spectacular: A series of different studies using different instructors and implemented in very different states across India found that the program significantly improved learning outcomes (Banerjee et al 2017).
Back in Kenya, academics worked with an NGO to test an alternative way to “teach at the right level,” sorting grade 1 children into two classes based on their level of English skills and adjusting the curriculum to adapt to each class’s basic skills. The evaluation found that students in both classes learned more (Duflo, Dupas, and Kremer 2011).
Here, although the Kenyan program was quite different from the Indian program, the theory behind the programs’ effectiveness—adapting curriculum to teach students at their current skill level—was consistent across contexts.
Similarly, a review of education technology shows that the most consistent gains come not from simply putting computers in classrooms, but from improving access to personalized learning software on computers or tablets that seeks to tailor learning to the skills of the child—in other words, teaching at the right level (Escueta et al 2017). Some of these computer programs were inspired in part by lessons from noncomputer based teaching at the right level studies.
In meetings between J-PAL and the Ministry of Education in Zambia, ministry officials noted that children were going to school regularly but falling behind the curricula, and that there was a wide range of learning levels in the same class. Given the wide evidence base from different programs that the “teaching at the right level” approach was likely to improve student learning, the question for Zambia was which type of “teaching at the right level” program made sense in their context. To find out, the government piloted a number of different programs.
We conducted a process evaluation to test whether children turned up and whether teachers taught at the right level for children, because these were the crucial questions in this context. The program found to be most appropriate is being scaled up to 1,800 schools in Zambia over the next three years, with potential for further scale based on the results of an ongoing randomized evaluation.
My final example doesn’t even involve testing a program, yet it is probably the example in which evidence has had a direct impact on the most lives.
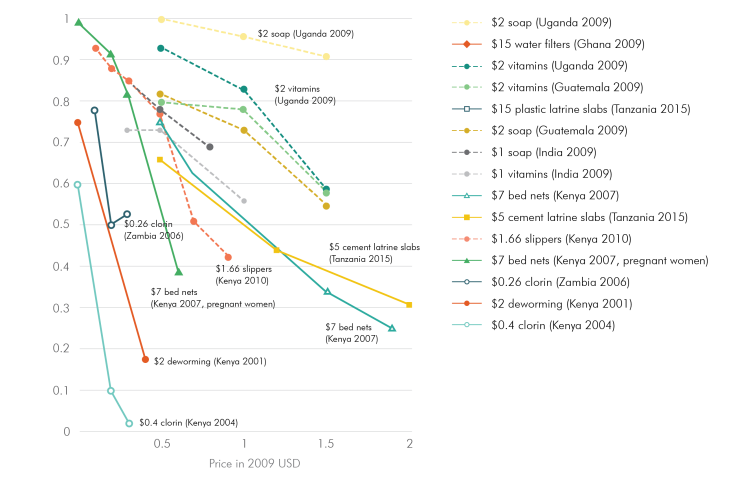
In 2000 there was an intense argument about whether malarial insecticide-treated bednets (ITNs) should be given out for free. Some argued that charging for bednets would massively reduce take-up by the poor. Others argued that if people don’t pay for something, they don’t value it and are less likely use it. It was an evidence-free argument at the time.
Then, a series of studies in many countries testing many different preventative health products showed that even a small increase in price led to a sharp decline in product take-up. Pricing did not help target the product to those who needed it most, and people were not more likely to use a product if they paid for it. This cleared the way for a massive increase in free bednet distribution (Dupas 2011 and Kremer and Glennerster 2011).
There was a dramatic increase in malaria bednet coverage between 2000 and 2015 in sub-Saharan Africa. At the same time, there was a massive fall in the number of malarial cases. In Nature, Bhatt and colleagues estimate that the vast majority of the decline in malarial cases is due to the increase in ITNs. They estimate there were 450 million fewer cases of malaria due to ITNs and four million fewer deaths due to ITNs. The lesson here is that testing an important policy-relevant idea can have as much impact on peoples’ lives as testing a specific program.
As we think about investing in high-quality evidence for development and using the results of those investments, we need to avoid relying upon a single simplistic model for how evidence is used to improve lives.
Sometimes we do research to test a specific program in the hope that the program can be scaled up. But much of what we learn from RCTs and other rigorous methodologies is about general behavior—for example, people are highly sensitive to prices when it comes to preventative health, and the incentives in school systems often mean teachers teach to the top of the class while children find it hard to learn when the curricula is above their level of learning.
For funders, three concluding lessons from observing and participating in using evidence to help improve millions of lives:
1. Stay open, not prescriptive, because it is hard to predict innovation. The varied models I describe above are indicative of the many different ways to innovate and improve lives at scale—and we are still learning.
2. Evidence is a global public good and its learnings go well beyond the specific program evaluated. Testing the theories behind programs has the potential to generate general and thus highly policy-relevant lessons applicable across contexts, and should be encouraged.
3. Incorporating theory-based lessons into policymaking requires a deep understanding of the evidence. Supporting technical assistance to help governments incorporate evidence into their policies is a high-payoff approach to catalyzing impact.
-
Cross-posted from Running Randomized Evaluations.


{kind=link}
{kind=link}
{kind=link}